Thread Pool: Implementing an Efficient Fork/Join Framework
My journey in squeezing out performance from my threadpool class project
In my Computer Systems class, we had four projects for the semester. Implementing a multi-threaded work-stealing thread pool was the second, releasing just a day before Fall breaks. At the start of the semester and throughout, everyone had their opinion about the ranking for the difficulty of the four projects. Project 2 was consistently ranked the hardest.
To be honest, I was excited before the project even started because this project had a performance based leader board!!!
And not only that, my roommate is also a year ahead and did this project before so that’s also another tangible target I need to be.
I was obsessed with the project and I’m here to share some of that.
1. Background
The Goal / Project Spec
The goal is relatively simple. We need to write a multi-threaded fork/join framework thread pool library. A fork/join framework is a model for parallelization where you have a task which recursively divides (fork) the task into smaller children tasks that can be executed in parallel. The results of the children tasks are then joined to get the answer.
The performance of the thread pool will then be tested on a couple parallelized algorithm like Merge Sort (MS), Quick Sort (QS), N-Queens (NQ), Simpson’s method (S), and Recursive Fibonacci (F). The performance on those tests will then be measured with 8, 16, and 32 cores. The tests are run on the school CPU cluster with dual-socket Intel Xeon CPUs with 16 cores each, providing 32 cores total.
Terminology before get technical
- Future: A struct containing the task (function pointer) and data (void pointer) that our thread pool will run.
- Thread Pool: Our struct that orchestrates running the futures submitted to it.
- Main Thread: The original thread running the user code that instantiated our thread pool
- Worker Thread: Threads spawned to do work submitted to the thread pool
2. Implementation
Work Stealing Thread Pool Architecture
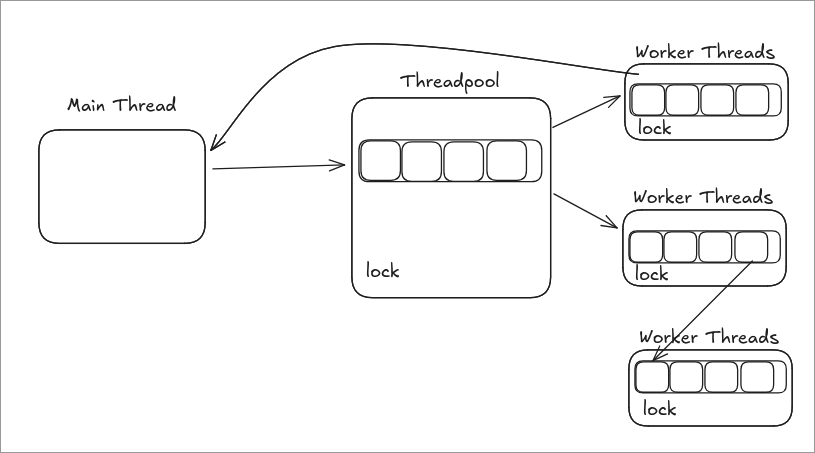
Figure 1: A diagram demonstrating the use of our thread pool. The main thread (user program thread that owns the thread pool) pushes futures to the thread pool. Worker threads take work from the thread pool queue. During execution, worker threads might spawn more futures, which are pushed onto their own worker queues. Idle workers who can’t find work in the main thread pool try to steal work from other worker queues.
The thread pool maintains a global queue where the main thread pushes tasks. Worker threads pull work from this global queue. When the global queue is empty, worker threads attempt to steal work from other threads. As worker threads execute tasks, they may generate subtasks which are submitted to their own worker queues, making these tasks visible to other worker threads for potential stealing.
Protecting your data with locks

Notice the inefficiency on the right…
Now, we could try and do without locks and I actually did try. It taught me several lesson. I might write a follow up blog post going into the experience but let us just follow the spec today.
We could try and give every future its own lock but that is unnecessary and we would be creating and destroying thousands of locks which is slow. Of course, the other end of the spectrum is a single global lock but that is also slow due to contention.
The middle ground:
- The thread pool has 1 lock protecting its struct data
- Each worker thread has 1 lock protecting its struct data
In our locking scheme, any access to a future requires acquiring the lock associated with it. This approach decreases the number of locks and alleviates the strain of maintaining hundreds of mutex locks on the OS. Since there are only n worker threads, it makes sense to keep the number of mutex locks to around n as well.
Furthermore, most of the time, each worker thread should be getting futures to execute from its own worker queue. This means that every worker thread should rarely have to access the lock of another thread meaning minimal contention … in theory.
3. Performance Features
Putting our threads to bed
To avoid wasting CPU time, we put our threads to sleep when there is no work:
- Workers sleep when there are no tasks anywhere (neither in the thread pool queue nor in other worker queues)
- The main thread sleeps while waiting for a task result, as tasks might take several seconds or minutes to complete
We use two conditional variables to handle these distinct sleep scenarios:
- When a task completes, we wake threads sleeping on conditional variable 1
- When a new task is submitted, we wake worker threads sleeping on conditional variable 2
Work Helping
When a worker thread needs the result of a task that no other thread has started working on, it will execute the task itself.
Work Stealing
When the thread pool queue is empty, a worker thread searches for work in other threads’ queues. Upon finding work, it steals the task and begins execution.
Helping Thieves
When a worker thread needs the result of a task that another thread has stolen and is running, the current worker thread will help the thief by stealing work from the thief’s queue.
4. Optimizations
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | 24.14 | 10.76 | 7.45 | 6.23 | 7.13 | 4.88 | 4.77 | 12.00 | 7.95 | 3.31 | 1.67 | 2.13 | 3.06 |
| Const variables | 24.43 | 10.79 | 7.46 | 6.26 | 7.11 | 4.90 | 4.85 | 11.98 | 7.90 | 3.29 | 1.69 | 2.25 | 3.17 |
| CPU Pinning | 16.75 | 9.76 | 6.63 | 5.17 | 6.66 | 4.55 | 3.94 | 9.39 | 4.96 | 3.30 | 1.68 | 1.26 | 1.42 |
| Delay Sleeping | 15.80 | 9.83 | 6.66 | 5.18 | 6.79 | 4.60 | 3.92 | 9.33 | 4.79 | 3.30 | 1.66 | 1.07 | 0.85 |
| False Sharing | 15.53 | 9.74 | 6.65 | 5.21 | 6.68 | 4.58 | 3.92 | 9.35 | 4.81 | 3.30 | 1.65 | 0.92 | 0.68 |
| Reduce Mutex Lock | 15.58 | 9.60 | 6.72 | 5.18 | 6.79 | 4.58 | 3.95 | 9.34 | 4.80 | 3.32 | 1.66 | 0.91 | 0.74 |
| int to uint | 15.53 | 9.88 | 6.68 | 5.18 | 6.73 | 4.60 | 3.93 | 9.34 | 4.79 | 3.33 | 1.65 | 0.88 | 0.76 |
The table summarizes the performance impact of each optimization
Note: Bold values indicate best performance for that benchmark.
Making Fields Constant Where Possible
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | 24.14 | 10.76 | 7.45 | 6.23 | 7.13 | 4.88 | 4.77 | 12.00 | 7.95 | 3.31 | 1.67 | 2.13 | 3.06 |
| Const variables | 24.43 | 10.79 | 7.46 | 6.26 | 7.11 | 4.90 | 4.85 | 11.98 | 7.90 | 3.29 | 1.69 | 2.25 | 3.17 |
In my worker struct, I have two fields that remain unchanged throughout program execution: the pointer to the thread pool it belongs to and the worker ID. By making these constant, I aimed to enable additional compiler optimizations:
struct worker {
struct thread_pool* const pool;
struct list q;
pthread_mutex_t lock;
pthread_cond_t cond;
const int wid;
};Result: This optimization produced minimal performance difference. While disappointing, it seems there wasn’t much more the compiler could optimize even with these const declarations, since the values are still unknown at compile time.
CPU Pinning
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Const variables | 24.43 | 10.79 | 7.46 | 6.26 | 7.11 | 4.90 | 4.85 | 11.98 | 7.90 | 3.29 | 1.69 | 2.25 | 3.17 |
| CPU Pinning | 16.75 | 9.76 | 6.63 | 5.17 | 6.66 | 4.55 | 3.94 | 9.39 | 4.96 | 3.30 | 1.68 | 1.26 | 1.42 |
When a worker thread is moved from one CPU core to another, it suffers from:
- Loss of access to warmed L1/L2 cache, increasing memory access time
- Required reloading of TLB buffer entries
- Relocation of context switches and loss of branch prediction data
By pinning worker threads to specific CPU cores, we can avoid these performance penalties:
static void pin_thread(pid_t thread_id, int core) {
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(core, &mask);
sched_setaffinity(0, sizeof(mask), &mask);
}Result: This optimization made a dramatic difference, significantly improving performance across essentially all benchmarks.
Delayed Sleeping Strategy
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CPU Pinning | 16.75 | 9.76 | 6.63 | 5.17 | 6.66 | 4.55 | 3.94 | 9.39 | 4.96 | 3.30 | 1.68 | 1.26 | 1.42 |
| Delay Sleeping | 15.80 | 9.83 | 6.66 | 5.18 | 6.79 | 4.60 | 3.92 | 9.33 | 4.79 | 3.30 | 1.66 | 1.07 | 0.85 |
Through some testing, I found that busy waiting was significantly faster than putting threads to sleep. However, busy waiting consumes CPU time that could impact other processes. My solution was to implement a hybrid approach: adding a soft counter that only puts a thread to sleep after it fails to find work a certain number of times.
// worker event loop
while (true) {
// get work from thread pool queue
// work stealing
// check not shutdown
if (fail_cnt == 100) {
fail_cnt = 0;
if (list_empty(&pool->q)) {
// go to sleep
pthread_cond_wait(&pool->worker_cond, &pool->lock);
}
}
fail_cnt++;
}Result: This optimization captures some of the performance benefits of busy waiting without its downsides, showing impressive improvements in several benchmarks.
Preventing False Sharing
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Delay Sleeping | 15.80 | 9.83 | 6.66 | 5.18 | 6.79 | 4.60 | 3.92 | 9.33 | 4.79 | 3.30 | 1.66 | 1.07 | 0.85 |
| False Sharing | 15.53 | 9.74 | 6.65 | 5.21 | 6.68 | 4.58 | 3.92 | 9.35 | 4.81 | 3.30 | 1.65 | 0.92 | 0.68 |
When a value changes, it invalidates all other values in the same cache line (false sharing). By adding padding to each worker struct, we can ensure they don’t share cache lines:
#define CACHE_LINE_SIZE 64
typedef char cacheline_pad_t[CACHE_LINE_SIZE];
struct worker {
...
cacheline_pad_t pad1; // force new cache line
};
struct thread_pool {
...
struct worker workers[32] __attribute__((aligned(CACHE_LINE_SIZE)));
...
};Result: This optimization improved performance on several benchmarks by eliminating cache invalidation between worker structs.
Reducing Mutex Lock Operations
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| False Sharing | 15.53 | 9.74 | 6.65 | 5.21 | 6.68 | 4.58 | 3.92 | 9.35 | 4.81 | 3.30 | 1.65 | 0.92 | 0.68 |
| Reduce Mutex Lock | 15.58 | 9.60 | 6.72 | 5.18 | 6.79 | 4.58 | 3.95 | 9.34 | 4.80 | 3.32 | 1.66 | 0.91 | 0.74 |
When a thread runs a future, it typically follows this pattern:
- LOCK
- POP future from queue and SET future status to running
- UNLOCK
- Run computation
- Save result of computation
- LOCK
- SET future status to finished
- UNLOCK
The second pair of lock operations seems wasteful when we’re only changing a boolean variable. Using a memory barrier instead can ensure proper ordering without locks:
static inline void run_future(struct future* fut) {
assert(fut != NULL);
fut->ans = fut->task(fut->pool, fut->data);
// enforce the write to fut->ans is visible before write to fut->finish
atomic_thread_fence(memory_order_release);
fut->finished = true;
}Result: This optimization feels like it should improve performance but it’s not clear if it really improved anything.
5. Micro-Optimizations
Converting Signed Int to Unsigned Int
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| False Sharing | 15.53 | 9.74 | 6.65 | 5.21 | 6.68 | 4.58 | 3.92 | 9.35 | 4.81 | 3.30 | 1.65 | 0.92 | 0.68 |
| int to uint | 15.53 | 9.88 | 6.68 | 5.18 | 6.73 | 4.60 | 3.93 | 9.34 | 4.79 | 3.33 | 1.65 | 0.88 | 0.76 |
Examining the assembly code revealed a suspicious movslq %ebp,%rax instruction performing sign extension for the thief_id variable. Since we know thief_id is always positive, specifying this in the code by using an unsigned int eliminates the sign extension operation.
Before:
5.96 │ 60: mov 0x20(%rbx),%rdi
0.81 │ mov 0x4(%rbx),%ebp
2.83 │ → call pthread_mutex_unlock@plt
6.29 │ mov %fs:0xfffffffffffffff0,%rax
1.59 │ mov 0x28(%rax),%r12
17.66 │ movslq %ebp,%rax
│ lea (%rax,%rax,4),%rax
│ lea (%rax,%rax,4),%rbp
0.19 │ shl $0x3,%rbp
│ lea 0xc0(%r12,%rbp,1),%r13After:
3.33 │ 60: mov 0x20(%rbx),%rdi
1.66 │ mov 0x4(%rbx),%ebp
3.05 │ → call pthread_mutex_unlock@plt
4.51 │ mov %fs:0xfffffffffffffff0,%rax
2.26 │ mov 0x28(%rax),%r12
20.15 │ mov %ebp,%eax
│ lea (%rax,%rax,4),%rax
│ lea (%rax,%rax,4),%rbp
0.27 │ shl $0x3,%rbp
│ lea 0xc0(%r12,%rbp,1),%r13Result: This micro-optimization produced mixed results, with minimal overall impact. A single instruction optimization is relatively minor compared to the total CPU time spent on tasks.
Unsafe Reads Experiment
| Optimization | MQNSF | Real MS/8 | Real MS/16 | Real MS/32 | Real QS/8 | Real QS/16 | Real QS/32 | Real NQ/16 | Real NQ/32 | Real S/8 | Real S/16 | Real S/32 | Real F/32 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| False Sharing | 15.53 | 9.74 | 6.65 | 5.21 | 6.68 | 4.58 | 3.92 | 9.35 | 4.81 | 3.30 | 1.65 | 0.92 | 0.68 |
| Unsafe reads | 15.89 | 9.73 | 6.70 | 5.20 | 7.28 | 4.94 | 4.33 | 9.34 | 4.80 | 3.34 | 1.67 | 0.91 | 0.65 |
I attempted to simplify the future status checking code by using unprotected reads, reasoning that slightly out-of-date values would be acceptable since the loop would essentially be some kind of busy waiting.
Before:
if (isWorker) {
pthread_mutex_lock(fut->owner_lock);
if (fut->has_started) {
// Someone else stole our future
while (!fut->finished) { // keep stealing until whoever stole fut finishes
uint thief_id = fut->thief_id;
pthread_mutex_unlock(fut->owner_lock); // protect read of fut->finish end
struct worker* thief = &worker->pool->workers[thief_id]; // figure out who stole our future
f = steal_future(&thief->lock, &thief->q); // steal from the thief
if (f != NULL) {
run_future(f);
}
pthread_mutex_lock(fut->owner_lock); // protect read of fut->finish start
}
pthread_mutex_unlock(fut->owner_lock);
return fut->data_or_ans;
}
else {
// pop off queue and run
}
}After:
if (isWorker) {
if (fut->has_started) {
pthread_mutex_unlock(fut->owner_lock);
while (!fut->finished) { // unprotected read of fut->finished
uint thief_id = fut->thief_id;
struct worker* thief = &worker->pool->workers[thief_id];
f = steal_future(&thief->lock, &thief->q);
if (f != NULL)
run_future(f);
}
return fut->data_or_ans;
}
else {
// pop off queue and run
}
}Result: Surprisingly, this change made performance worse despite eliminating two mutex operations. This honestly doesn’t make sense but the data is consistent across multiple runs.
6. Other Optimizations Tried and flopped
Avoiding Unnecessary Queue Pushes
I attempted to optimize by not pushing futures to the worker queue when there were already enough tasks for other threads to steal:
struct future * thread_pool_submit(struct thread_pool *pool, fork_join_task_t task, void * data) {
if (isWorker) {
if (worker->queue_cnt < queue_size_limit) {
pthread_mutex_lock(fut->owner_lock);
list_push_front(&worker->q, &fut->elem);
pthread_cond_signal(&pool->worker_cond);
pthread_mutex_unlock(fut->owner_lock);
worker->queue_cnt++;
}
}
else {
// main thread code
}
}Result: The overhead introduced by the extra check outweighed any benefits. Additionally, since our thread pool implements work stealing, the queue_cnt value cannot be owned by a single thread, requiring atomic variables or locks to prevent race conditions.
Memory Reuse Instead of Malloc
I attempted to reuse memory instead of calling malloc for each new future:
static struct future* future_create(struct thread_pool *pool, fork_join_task_t task, void * data) {
// struct future* fut = malloc(sizeof(struct future));
struct future* fut;
if (isWorker) {
fut = stack_pop(&worker->stk);
}
else {
fut = stack_pop(&pool->stk);
}
// set up other variables
return fut;
}Result: This significantly worsened performance. I later learned that malloc already implements memory reuse internally through memory arenas, only calling the system when additional memory is needed from the kernel.
Fine-tuning Malloc Configuration
Since directly replacing malloc didn’t work, I tried configuring malloc options:
struct thread_pool * thread_pool_new(int nthreads) {
mallopt(M_TRIM_THRESHOLD, -1); // disable trimming of heap
...
}Result: This actually made performance worse, possibly because our workload doesn’t have cycles of increasing and decreasing heap size that would benefit from this optimization.
Reducing Future Struct Size
I explored four approaches to reduce the size of the future struct:
- Rolling boolean fields and thief ID into a status struct
- Combining data and ans fields since they’re never needed simultaneously
- Removing the pool pointer since workers already store it
- Using atomic status fields with futex to eliminate conditional and lock pointers
// Current future struct
struct future {
bool finished;
bool has_started;
fork_join_task_t task;
struct thread_pool* pool;
void* data;
void* ans;
pthread_mutex_t* owner_lock;
pthread_cond_t* fut_cond;
struct list_elem elem;
int thief_id;
};
// New future struct
struct future {
_Atomic struct status status;
fork_join_task_t task;
void* data_or_ans;
struct list_elem elem;
};Results when testing each optimization individually:
- Slower: Using bit fields requires reading the value and applying bit masks, making reading the finished variable slower
- Neutral: No measurable effect on performance
- Slower: Having the pool field in the future struct likely makes it already cached, thus faster compared to thread lookup
- Slower: Using futex requires the status variable to become atomic, which makes read/write operations slower
Despite profiling showing malloc and free operations taking up 10% of CPU time, these changes made performance significantly worse.
7. Conclusion on Optimization
The most impactful optimizations were CPU Pinning, Delayed Sleeping, and Preventing False Sharing. The more complex and clever optimizations I attempted generally failed to produce benefits.
A key insight is that the most effective optimizations were simple in implementation—often just 3-4 lines of code—focusing on fundamental hardware and OS interactions rather than complex algorithmic changes.
What I Would Do Next Time
This project revealed how unpredictable performance optimization can be. Intuition failed repeatedly, and seemingly obvious improvements often had negative impacts rather than helping.
For future projects, I would:
- Set up a more extensive measurement infrastructure to gain greater visibility into performance bottlenecks
- Implement comprehensive logging to track behavior in different scenarios
- Use more sophisticated profiling tools to identify genuine optimization opportunities
- Test each change in isolation on multiple machines in parallel for more consistent results
Optimizing this thread pool is honestly the most fun I ever had while coding. However, nothing makes sense! All my clever ideas become moot and I have no clue why. Then things I thought helped turned out to maybe not actually help when I tried reproducing the effect later and turned out to only be the result of jitter. I think this is the most I can do for now without going back to the drawing board and setting up the proper infrastructure to get more accurate and clearer results.